

İlk adım: verileri toplamak. Sağlıklı bir tahmin oluşturulması için ihtiyaç duyulan değişkenlere ait değerler içeren verilere ihtiyaç vardır. Bu veriler aracılığıyla modelimizi eğitir ve tahminler yapmasını sağlarız. Toplanılan verilerin miktarı ve niteliği modelin doğruluk oranını doğrudan etkiler. Toplanan veriler birbiri ardına sıralanarak bir tablo oluşturur.

En önemli basamaklardan biridir. Başarılı bir model oluşturmak için asla atlanmaması gereklidir. Başlangıç olarak verileri görselleştirmek değişkenler arası olası ilişkileri ve düzensizlikleri fark etmek için uygun bir adım olabilir. Örneğin pazartesi günlerine ait verilerin sayısının diğer günlere oranla çok daha fazla olması…
Ele alınması gereken bir başka husus ise veriyi eğitim (train) ve test seti olarak 2’ye ayırmak. Veri setinin büyük bir kısmı modeli eğitmek, geri kalan kısmı ise modeli test etmek ve doğruluk oranını görmek için kullanılır. Eğitim için kullanılan verileri tekrar test için kullanmak hiç sağlıklı sonuçlar doğurmayacaktır.
Ayrıca eksik verilerin incelenmesi, normalizasyon, aykırı verilerin incelenmesi gibi uygulanabilecek veri ön işleme basamakları bulunur.
3. adım: model seçimi. Araştırmacıların ve veri bilimcilerin ortaya koyduğu farklı ihtiyaçlar için ortaya konmuş birçok model bulunur. Bazı modeller daha karmaşık veri setleri üzerinde çok iyi çalışırken, bazıları basit sayılacak veri setleri üzerinde çok iyi çalışır; ancak karmaşık veri setlerinde çok iyi bir sonuç doğurmayabilir. Aynı şekilde verilerin türü (görsel, nümerik, metin veya müzik) de seçilmesi gereken modelin türünü etkiler.
Eğitim (train) veri seti yardımıyla modelin eğitildiği adımdır.
Örneğin Basit Doğrusal Regresyonu ele aldığımızı düşünelim. Basit doğrusal regresyonun tahmin modeli şu şekildedir;
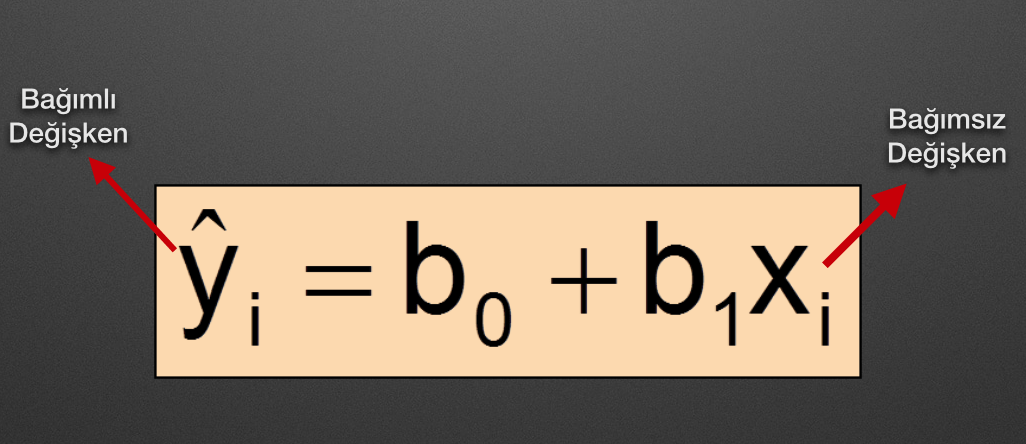
En başta ağırlık ve önyargı için random bir değer atanır, eğitimin her adımı bu değerler güncellenerek en doğru değerler yakalanmaya çalışılır.
Modelin eğitilmesi tamamlandıktan sonra test veri seti ile değerlendirme yapılır. (Test veri seti eğitimde kullanılmayan verilerden oluşmalıdır.) Bu sayede modelin daha önce karşılaşmadığı verilerle karşılaştığında üreteceği sonuçlar görülebilir. Modelin gerçek dünyada üreteceği sonuçların temsili niteliğinde olduğu söylenebilir.
6. 6. Parametre İyileştirmeleri (Parameter Tuning)
Modeli daha doğru hale getirmek, doğruluk oranını arttırmak için tuning işlemi yapılır. Bu işlemde modelin hiperparametrelerine verilen değerlerin olası sonuçları karşılaştırılarak en iyisi bulunmaya çalışılır. Bu hiperparametreler kullanılan modele bağlı olarak değişebilir. Örneğin Gradient Boosting Machines’de “learning_rate, n_estimators, subsample” gibi hiperparametrelerin en iyi değerleri araştırılarak modelin doğruluğu artırılabilir.
7. 7. Tahmin (Prediction)
Modelin amacını yerine getirdiği adımdır. Modelin tahminler yaparak sorularımıza cevap verdiği, ele alınan problemin çözümü için kullanıldığı adımdır.
Kaynaklar: Google Cloud Platform, The 7 steps of Machine Learning















{kind=link}
{kind=link}